
データソリューション部 チーム田中の森田です。
Oracle Big Data Cloud Compute Edition インスタンス作成について、前回に引き続き検証を行っていきます。
“無償”でクラウド移行の意思決定に必要な情報を提供
OCIに特化した無償移行アセスメントサービス
「高品質・低コストなOracle Cloudに移行したいがノウハウがない」「まだ比較検討段階で外部にアセスメントを依頼する予算がない」「まるっとクラウド移行を任せられるベンダーが欲しい」などのお困りごとは、ぜひ私たちシステムエグゼへご相談ください。
3回のワークショップでスピーディーにお客さまのシステムのアセスメント結果をご提供します!

BDCSCEインスタンス作成
事前作成が必要なリソースを作成できたので、いよいよインスタンスを構築します。必要事項を記入し、作成を押下するのみです。実際の構築には約30分程度かかります。
ステップ1:インスタンス作成画面遷移
BDCSCE作成画面はOCIメニューの下記画面赤枠の箇所にあります。
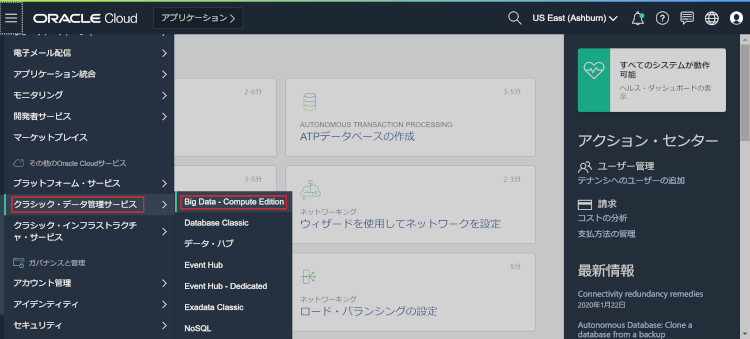
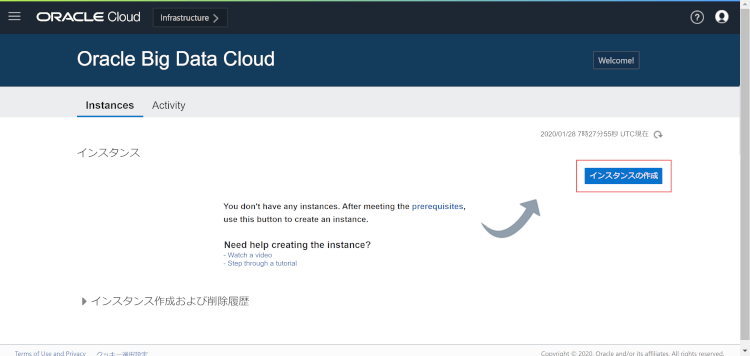
右上にあるインスタンスの作成を押下します。
ステップ2:必要事項記入
記入画面は2つあります。まずはインスタンス名、リージョン等を設定します。
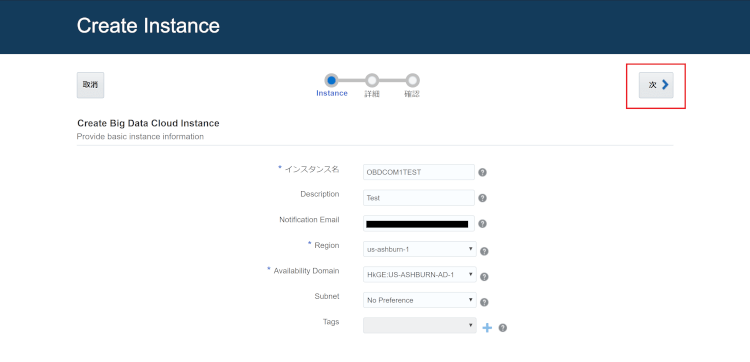
| インスタンス名 | インスタンス名を任意で記入(必須) |
|---|---|
| Descriotion | インスタンス説明 |
| Notification Email | インスタンス作成等の通知先 |
| Region | インスタンス作成先リージョン(必須) |
| Availability Domain | インスタンス作成先リージョン内の 可用性ドメイン選択(必須) |
| Subnet | インスタンス作成するPaaS用サブネット 『No Preference』選択時は デフォルトPaaS用サブネットを選択 |
| Tags | インスタンスに付与するタグを設定 |
次にHadoopクラスタ構成、ストレージ構成、認証情報といった詳細を設定します。ここで前もって作成したOCIユーザーとオブジェクトストレージバケットの情報を記入していきます!
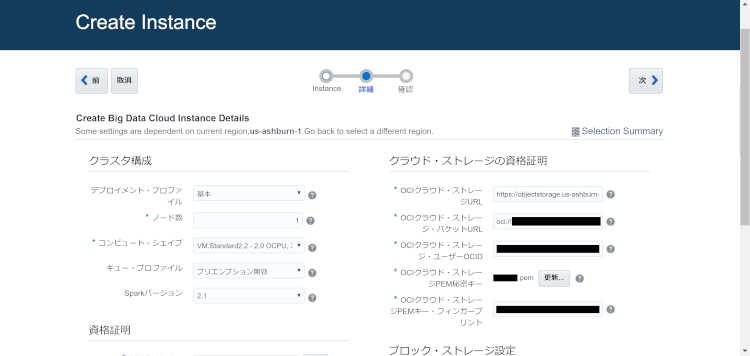
記入事項が多いので、順々に解説していきます。
クラスタ構成
| デプロイメント・プロファイル |
インスタンスコンポーネント構成を設定する。
|
|---|---|
| プロファイル ノード数 | Hadoopクラスタ個数を設定、最小値は1 |
| コンピュート・シェイプ | Hadoopクラスタを構築する仮想サーバのスペックを選択 |
| キュー・プロファイル | キューのタイプを選択 |
| Sparkバージョン | Sparkのバージョンを1.6または2.1から選択 |
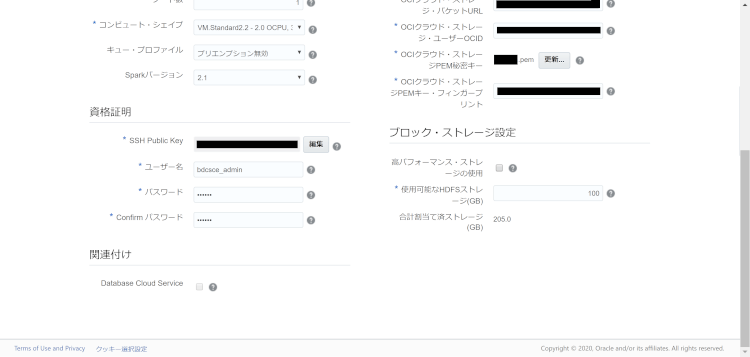
資格証明
| SSH Public Key |
仮想サーバ(OCIのコンピュートインスタンス) |
|---|---|
| ユーザー名 | BDCSCE管理コンソールログイン時に使用する 管理者ユーザー名を設定。 デフォルトは『bdcsce_admin』 |
| パスワード | BDCSCE管理コンソールログイン時に使用する 管理者ユーザーのパスワードを設定。 |
| Confirm パスワード | 設定したパスワードを再度入力 |
関連付け
| Database Cloud Service |
既存のDBCSとの関連付け設定。 |
|---|
クラウド・ストレージの資格証明
| OCIクラウド・ストレージURL |
バケットを作成したリージョンの |
|---|---|
| OCIクラウド・ストレージ・バケットURL | 作成したバケットへアクセスするURLを入力。 形式は下記の通り。 『oci://【バケット名】@【テナント名】/』 |
| OCIクラウド・ストレージ・ユーザーOCID | 作成した別途へアクセスするユーザーのOCIDを入力 |
| OCIクラウド・ストレージPEM秘密キー | バケットへアクセスするユーザーに紐づけた 公開鍵に対となる秘密鍵を登録 (OCIユーザとAPI接続の準備) |
| OCIクラウド・ストレージPEMキー・フィンガープリント | バケットへアクセスするユーザーに紐づけた 公開鍵登録時に出力された フィンガープリントを入力 |
ブロック・ストレージ設定
| 高パフォーマンス・ストレージの使用 |
HDFS用の高パフォーマンス・ストレージの使用設定。 |
|---|---|
| 使用可能なHDFSストレージ(GB) | HDFS用に割り当てるストレージサイズ。 |
| 使用可能なBDFSキャッシュ(GB) | HDFS用に割り当てるキャッシュサイズ。 |
ステップ3:作成前のサマリー確認
設定した内容を再確認し、問題なければ作成を押下します。
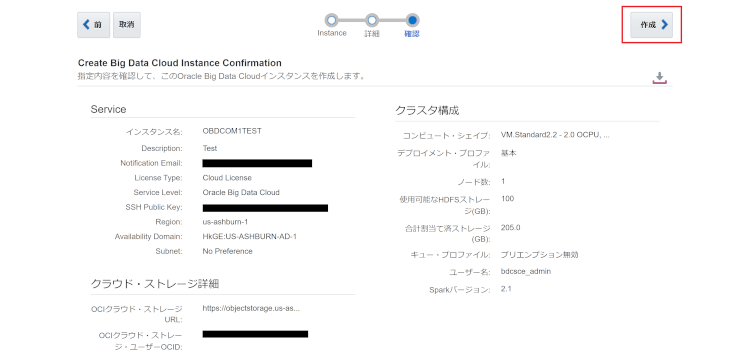
これでインスタンスが作成されます。

作成環境とWebコンソールへの接続確認
Compute EditionはComputeインスタンス同様、デフォルトでopcユーザが利用できるのでこちらでSSHログインできます。接続できることを確認しましょう。
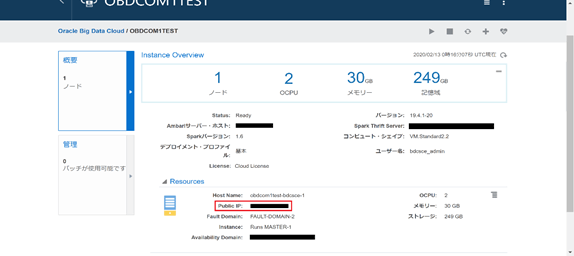
作成したインスタンスの詳細画面にアクセス用のパブリックIPが表示されています。このIP宛てにopcユーザでログインするようSSHを実行します。公開鍵で接続します。
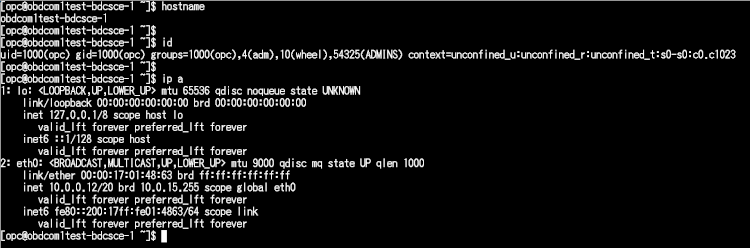
また、Webコンソールには下記からアクセス可能です。
Webコンソールではジョブの管理、オブジェクトストレージのバケットにアップされたファイルの確認、ノートブックによる分析等が利用可能です。
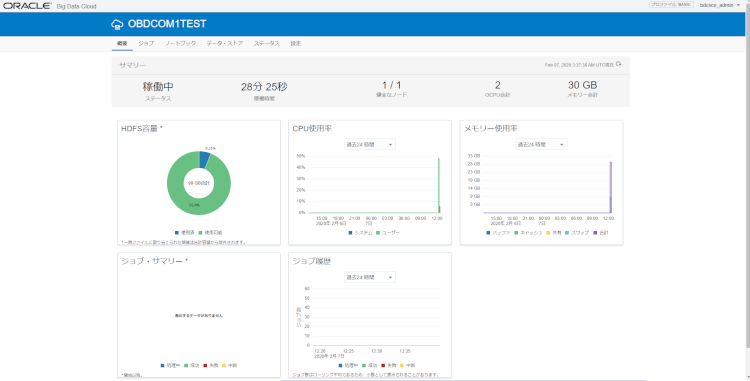
インスタンスの構築はこれで完了です!お疲れ様でした。
最後に
ビッグデータ処理のため、あらゆるOCIコンポーネントが必要となりますが、それぞれの手順自体は易しいものであり、ビッグデータ分析をスモールスタートしたいそんな要望にぴったり合うサービスであると、構築して思いました。
分析基盤構築は予算や工数等の課題が多く出るかと思われます。次回は、弊社内でHadoopクラスタをオンプレ上に構築し、BDCSCEインスタンスと諸観点から比較考察を行う記事を投稿予定です。
それでは、次回をお楽しみに!







